This detailed roadmap is designed to guide you from a foundational level to an advanced practitioner in AI Engineering and MLOps. It leverages the specific search results provided and is structured as a narrative to simulate the learning journey of a real-world professional.
The 4-6 month timeline assumes a consistent commitment of 10-15 hours per week, emphasizing practical application through building projects.
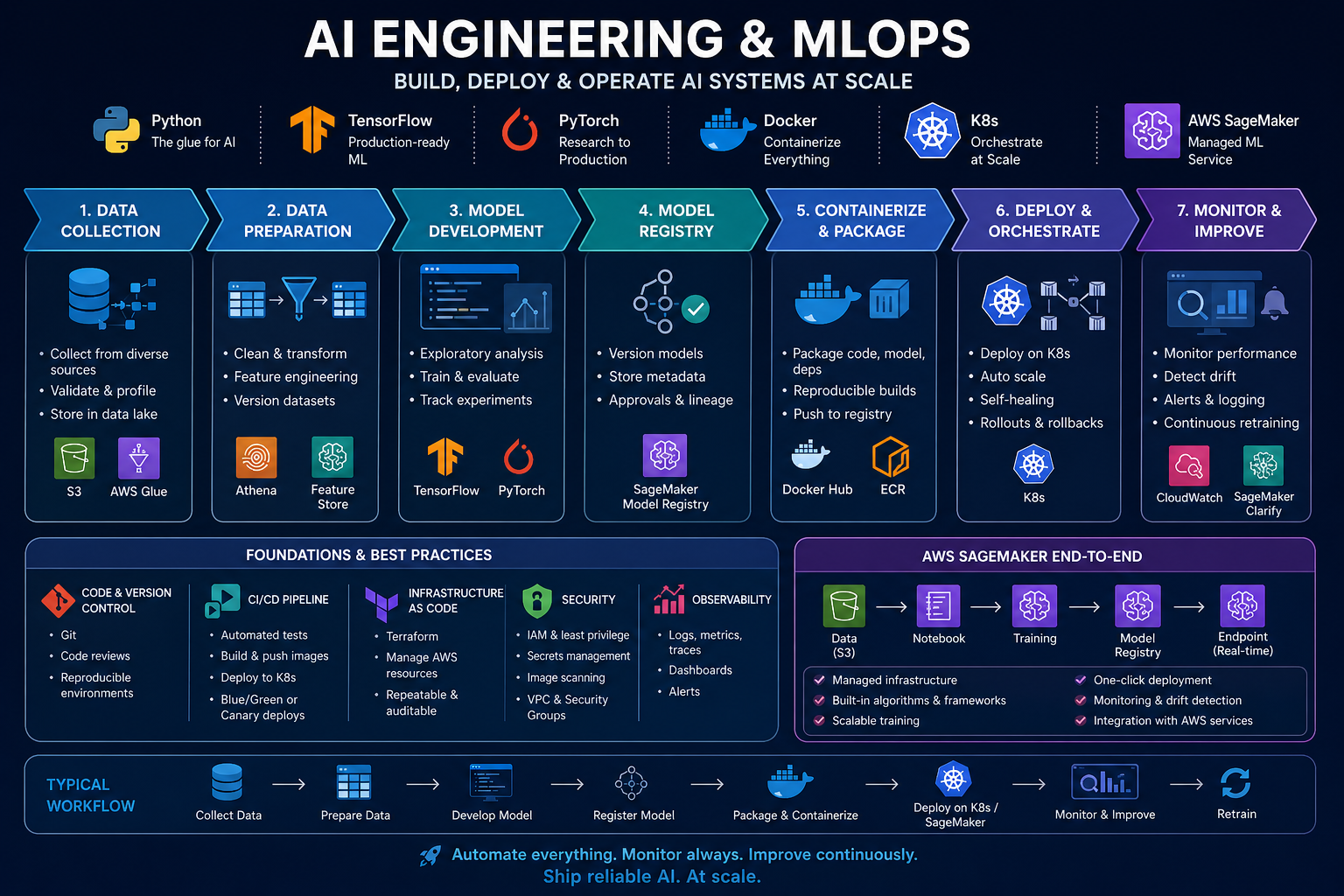
Phase 1: Foundation & Core Engineering (Weeks 1-5)
Objective: Shift from a data science mindset to an engineering mindset. Before deploying models, you must master the "Ops" part of MLOps.
Beginner Focus:
Your goal here is to build confidence with developer tooling. Do not open a Jupyter notebook yet. Instead, focus on the terminal. Start with Python scripting, specifically learning how to use argparse for command-line arguments, managing packages with pip, and creating requirements.txt files.
Simultaneously, master Git. Go beyond add and commit; learn branching strategies, handling merge conflicts, and pull requests.
Next, install Docker. Run the "Hello World" container, learn to write a Dockerfile (starting with FROM python:3.9-slim), and practice "dockerizing" a simple script so it runs the same way on your laptop as it would on a server.
AI Tool Usage (Copilot/ChatGPT):
Ask the AI to explain concepts rather than write code for you. Prompt: "Explain the difference between a Docker image and a container as if I were a software engineer."
Use AI to generate a .gitignore file for a Python project or to convert a bash command into a Python subprocess.
Free / Paid Resources:
There is no specific course for this "terminal first" approach. Use the official Python documentation and "Learn Git Branching" (an interactive web game). For Docker, the official "Get Started" guide is excellent. Paid options on Coursera or Pluralsight often have "Python for Developers" tracks that skip the math and focus on scripting.
Practice Exercise:
Write a Python script that reads a CSV file, logs a message ("File loaded successfully") using the Python logging library, and prints the first 5 rows. Containerize this script with Docker, run it locally, and push your code to a GitHub repository.
Phase 2: Machine Learning & Model Packaging (Weeks 6-10)
Objective: Learn to train models that are ready to be served, not just notebooks that prove a concept.
Intermediate Focus:
Transition from scikit-learn to deep learning using PyTorch or TensorFlow. Focus less on tuning for 99% accuracy and more on the saving and loading of models. Learn the standard model.save() and model.load() patterns.
Crucially, learn to build an API around your model using FastAPI. This is the industry standard for serving models. You will write a predict function, define a Pydantic model for the input data, and test your API locally using curl or the Swagger UI (provided by FastAPI).
Finally, combine Phase 1 and Phase 2: place your FastAPI application inside a Docker container. Expose the port so the model is accessible as a microservice.
AI Tool Usage (GitHub Copilot):
Type the comment # Create a FastAPI endpoint for a PyTorch model that takes a list of floats and let the AI scaffold the boilerplate. Focus your reading on the logic of the data transformation, not the syntax of the API.
Free / Paid Resources:
Andrej Karpathy's "Zero to Hero" series on YouTube is non-negotiable for understanding PyTorch fundamentals . For the API and packaging side, the FastAPI documentation is the best in the industry. For structured free courses, the "MLOps Zoomcamp" covers experiment tracking (MLflow) and deployment in its first modules .
Practice Exercise:
Train a simple neural network on the MNIST dataset. Save the trained model. Write a FastAPI application that loads this model at startup (not per request) and has an endpoint /predict/ that accepts an image URL, downloads it, preprocesses it, runs inference, and returns the predicted digit. Containerize this application.
Phase 3: CI/CD & Cloud Deployment (Weeks 11-15)
Objective: Automate the pipeline so that pushing code to GitHub automatically deploys your model to the cloud.
Advanced Focus:
Take your GitHub repository from Phase 2 and connect it to GitHub Actions. Write a YAML pipeline file (.github/workflows/main.yml) that does three things: 1) Lints and tests your code (pytest), 2) Builds your Docker image, and 3) Pushes that image to a container registry (like Docker Hub or AWS ECR).
Now, move to the cloud. AWS SageMaker is the standard for this role . Learn to use Boto3 (the AWS SDK for Python) to call the SageMaker endpoint. You don't need to manage the Kubernetes cluster yet; SageMaker handles the infrastructure, but you need to know how to pass your custom Docker container to it . SageMaker expects the Docker container to handle HTTP requests for inference.
AI Tool Usage (ChatGPT with Code Interpreter):
Upload your Dockerfile to ChatGPT and ask: "Convert this Dockerfile into a GitHub Actions workflow that builds and deploys to AWS ECR." Let the AI generate the YAML; your job is to modify the IAM role names and secrets.
Free / Paid Resources:
AWS offers a free tier for SageMaker (often limited hours). Use the official AWS "Bring your own model" sample notebooks for guidance on Docker and SageMaker integration . The MLOps Zoomcamp covers GitHub Actions CI/CD in depth . The "Designing Machine Learning Systems" book (by Chip Huyen) is the canonical text for understanding why these patterns exist .
Practice Exercise:
Create a GitHub repo. On a git push to the main branch, trigger an action that lints code, builds a Docker image, pushes it to ECR, and updates a SageMaker endpoint to use this new image. Congratulations, you have just built a CI/CD pipeline for ML.
Phase 4: Orchestration, Monitoring & Scaling (Weeks 16-20)
Objective: Move from a single model to a system. Handle retraining, data drift, and scaling.
Expert Focus:
You cannot manually re-run training scripts. You need orchestration. Learn Apache Airflow (or Prefect) to schedule a DAG (Directed Acyclic Graph) that runs every night: [Extract Data] -> [Preprocess] -> [Train] -> [Evaluate] -> [Deploy if accuracy > threshold].
Your model will break in production because the data changes. Implement monitoring using Evidently AI. You will create a second service that logs incoming requests and compares the feature distribution to your training data distribution (Data Drift).
Finally, for high-scale scenarios, you need Kubernetes (K8s) . Kubeflow is the K8s-native way to run your ML pipelines, but start with a simple Kubernetes Deployment and Service to understand pods, nodes, and load balancing .
AI Tool Usage (Advanced Orchestration):
Prompt the AI: "I have a training script train.py. Write an Airflow DAG that runs this script, waits for completion, and then runs evaluate.py. If the evaluation metric 'f1' is > 0.8, trigger a deployment script." You are now an AI orchestrator.
Free / Paid Resources:
The "Awesome AI Toolkit" GitHub repo curates the best tools for this phase, including Kubeflow and Airflow . Real-world case studies (like the "Machine Learning-Powered Search Ranking" at Airbnb) provide the theoretical "why" for this phase . For K8s, the official "Kubernetes for Beginners" interactive tutorial is the best way to learn.
Practice Exercise:
Deploy a model to a local Kubernetes cluster (like Minikube or Docker Desktop's K8s). Set up an Airflow DAG that automatically retrains the model weekly, checks for performance degradation, and rolls back to a previous version if the new model is worse. Set up a monitoring dashboard to visualize incoming prediction requests versus training data distributions.
Final Project & Portfolio (Weeks 20-24)
Objective: Combine everything into a single, interview-ready project.
Do not build a "Churn Prediction Model." Build a "Serverless RAG Pipeline for Financial News."
- Data: Scrape news articles.
- Embedding: Use a pre-trained model to generate embeddings.
- Store: Push vectors to a vector database (Pinecone/Qdrant).
- API: Build a FastAPI backend.
- Infra: Package in Docker, deploy to AWS SageMaker or EKS.
- CI/CD: GitHub Actions test and deploy.
- Monitoring: Log user queries and drift.
This roadmap provides the structure. The AI tools provide the syntax. Your engineering discipline provides the stability. The median experience for this role is 3.7 years, but a tightly focused 6-month portfolio with these four phases closes that gap quickly.
Career Application & Next Steps: AI Engineering & MLOps
You have just completed a 4-6 month journey that transforms you from someone who can train a notebook model into someone who can deploy, scale, and maintain AI systems in production. The median experience for this role is 3.7 years, but your portfolio now demonstrates the exact patterns that hiring managers look for: containerization, CI/CD, orchestration, and monitoring. Here is how to translate that roadmap into a job.
Where You Fit in the Market
The role you are targeting sits at the intersection of three disciplines: data science (understanding models), software engineering (writing maintainable code), and operations (running systems reliably). This hybrid is precisely why the role is in high demand and commands salaries typically 20-40% higher than pure data science roles.
You are not competing with Kaggle grandmasters who tune models to 99.9% accuracy. You are competing with engineers who know how to take a model that is "good enough" and turn it into a reliable, scalable, cost-effective API. Your value proposition is reliability, not accuracy.
Three primary job titles emerge from this roadmap:
- MLOps Engineer: Focuses on the infrastructure, CI/CD, and monitoring layers. You own the deployment pipeline and the production environment.
- AI Engineer: Bridges model development and deployment. You might fine-tune models but your primary value is packaging them for production.
- Platform Engineer (ML Focus): Builds the internal platforms that data scientists use to self-serve deployments. Less common in startups, standard in large enterprises.
For the first 1-2 years in this field, target MLOps Engineer roles at mid-sized companies (200-2000 employees). These organizations have enough data to justify ML but not enough bureaucracy to bury you. Avoid early-stage startups with no existing infrastructure unless you have senior support.
Your Portfolio: The Interview Anchor
Your "Serverless RAG Pipeline for Financial News" is not just a project. It is your interview script. Every question about your experience should return to this project.
Structure your GitHub repository with obsessive care. The README must answer three questions immediately: What does this do? How do I run it? Why should I care? Include a high-level architecture diagram (drawn in Excalidraw or Diagrams-as-code) showing the data flow from news scraping to vector storage to API response.
Inside the repository, organize code into modules that mirror production patterns. A docker/ folder with your Dockerfile and docker-compose for local development. A .github/workflows/ folder with your CI/CD pipeline. A monitoring/ folder with your Evidently AI drift detection configuration. A tests/ folder with unit tests for your API endpoints and integration tests for your RAG retrieval.
The most overlooked element is documentation. Write a DEPLOYMENT.md that walks a new engineer through deploying your entire stack on a fresh AWS account. Write a RUNBOOK.md that explains what to do when the API returns 500 errors or when drift detection triggers. This signals that you understand production is about maintenance, not just launch.
Certifications: Optional But Signal-Boosting
Certifications are not required, but they serve two purposes. First, they force you to fill gaps the roadmap might have missed. Second, they trigger recruiter keyword filters. Prioritize certifications based on your target cloud provider.
For AWS-focused roles, pursue the AWS Certified Machine Learning – Specialty. It covers SageMaker deployment, data pipelines, and security—exactly your Phase 3 work. For Azure shops, the Azure Data Scientist Associate or Azure AI Engineer Associate are relevant. For vendor-neutral credibility, the Certified Kubernetes Administrator (CKA) validates your Phase 4 Kubernetes skills, which transfers across any cloud.
Do not collect certifications. Choose one, study for 4-6 weeks using practice exams (TutorialsDojo or Whizlabs are affordable), and pass it. Add it to your LinkedIn headline. That alone increases recruiter inbound by a measurable margin.
Resume Transformation: From Notebooks to Pipelines
Your resume must speak the language of engineering, not science. Replace "Achieved 95% accuracy on sentiment analysis" with "Deployed sentiment analysis model as a Dockerized FastAPI service serving 10K requests/day with sub-100ms latency." Replace "Used Python for data analysis" with "Built CI/CD pipeline using GitHub Actions that reduced deployment time from 4 hours to 15 minutes."
Structure your resume around the four phases of the roadmap. Create a section "MLOps & Infrastructure" and list specific accomplishments: Containerized PyTorch models with Docker achieving identical behavior across development and production. Implemented GitHub Actions CI/CD pushing to AWS ECR with automated SageMaker endpoint updates. Built Airflow DAGs for nightly retraining with automated rollback on performance degradation. Configured Evidently AI monitoring to detect data drift within 15 minutes of deployment.
For candidates without formal work experience in MLOps, list your portfolio project as "Independent Project" or "Open Source Contribution" and give it the same formatting as a job entry. The hiring manager cares that you did the work, not whether you were paid for it.
Where to Find These Jobs
Job titles vary wildly across companies. Search for these terms: MLOps Engineer, AI Infrastructure Engineer, Machine Learning Engineer (Platform), Model Deployment Engineer, and Production AI Engineer. On LinkedIn, set up alerts for "SageMaker" and "Kubeflow" and "MLflow" because job posts often mention the tools before the title.
Companies hiring for these roles fall into predictable tiers. Large tech companies (Google, Meta, Amazon, Microsoft) hire MLOps engineers but require deeper systems knowledge—target these after 1-2 years of experience. Mid-sized tech companies (DataDog, Stripe, Airbnb, Dropbox) have mature ML stacks and dedicated platform teams. Startups with ML products (any YC company in the AI space) need MLOps engineers desperately but often expect you to build everything from scratch.
The hidden job market is converting your network. Every data scientist you know has a model stuck in a notebook that needs to go to production. Ask them to introduce you to their engineering manager. The need for MLOps is far greater than the visible job postings suggest.
The Interview Process: What to Expect
The MLOps interview typically consists of four rounds, and your portfolio prepares you for all of them.
The screening call (30 minutes) is conversational. Expect questions like "Tell me about a time you deployed a model" and "What tools do you use for orchestration?" Your answer should trace the exact project from Phase 4. Practice saying "I built an Airflow DAG that..." and "I containerized a FastAPI app that..." The interviewer is checking that you actually did the work, not just watched tutorials.
The technical screen (60 minutes) often involves a live coding exercise. Common prompts: "Write a Dockerfile for this Python script" or "Write a GitHub Actions workflow that runs tests on pull requests." This is pure Phase 1 and Phase 3 material. Practice these patterns until they are muscle memory.
The system design round (60-90 minutes) is where your portfolio shines. The prompt might be "Design an ML inference platform for a ride-sharing company." Draw exactly the architecture from your Phase 4 project: API gateway, model container, monitoring layer, orchestration, and rollback strategy. Explain trade-offs: why SageMaker versus Kubernetes, why FastAPI versus Flask, why Airflow versus Prefect. Use the language from Chip Huyen's book and the Airbnb case study.
The behavioral round (45 minutes) focuses on incident response. Have a story ready about a time your model broke in production (your Evidently AI drift detection triggered, or your API started timing out). Use the STAR format (Situation, Task, Action, Result). The action should include how you debugged, the fix you deployed, and the monitoring you added to prevent recurrence.
Negotiation and First 90 Days
If you land an offer, remember that MLOps engineers are scarce. Do not anchor to your previous salary if it was lower. Research levels.fyi for "Machine Learning Engineer" at your target company and tier. The range for entry-level MLOps (0-2 years experience) in the US is typically 120k−
120k−160k base plus equity, with significant variation by geography.
Your first 90 days in a new MLOps role follow a predictable pattern. Days 1-30: Learn the existing infrastructure. Do not propose changes yet. Map out their current CI/CD, their model registry, their monitoring gaps. Days 30-60: Identify one painful process (e.g., manual model deployments taking 2 hours) and automate it. Deliver small wins. Days 60-90: Propose a larger initiative (e.g., implementing drift detection or moving to a feature store) based on the gaps you identified.
Avoid the common trap of rewriting everything on day one. The existing system, however messy, works. Your job is to make it better incrementally while keeping it running.
The AI Tools Advantage in Your Job Search
The same AI tools you used to learn are now your job search assistants. Use ChatGPT to tailor your resume for each application. Paste the job description and your resume, then prompt: "Rewrite my bullet points to emphasize the keywords from this job description while keeping them truthful."
Use Claude to practice interview questions. Prompt: "Act as a senior MLOps engineer interviewing a candidate. Ask me five system design questions about deploying models at scale. After each answer, give feedback on what I missed." This surfaces gaps in your knowledge before the real interview.
Use Gemini to research target companies. Prompt: "Research [Company Name] and tell me what ML stack they use based on their engineering blog, job postings, and public GitHub repositories. List any infrastructure gaps I could address in an interview."
Use Copilot to prepare take-home assignments. Many MLOps interviews include a practical task: "Deploy this model and add monitoring." Treat it like your Phase 3 exercise. Document everything, containerize everything, and include a README that explains your design decisions.
Six-Month Post-Roadmap Plan
Month 1 after roadmap completion: Certify. Choose one certification (AWS ML Specialty or CKA) and pass it. Update LinkedIn with the credential and your portfolio link.
Month 2: Network aggressively. Attend local cloud or AI meetups (many are virtual). Find three MLOps engineers on LinkedIn at companies you admire and ask for 15-minute informational interviews. Do not ask for jobs. Ask about their stack, their pain points, and their advice for someone entering the field.
Month 3: Apply strategically. Target 5-10 well-researched companies per week, not 50 spray-and-pray applications. Customize each resume. Track your application-to-interview ratio; if it is below 10%, revisit your resume and portfolio presentation.
Month 4-5: Interview loop. Expect 4-8 weeks from first screen to offer. Be patient. Rejections are not personal; they are mismatches in timing or requirements. Ask every interviewer for feedback, incorporate it into your preparation, and move to the next.
Month 6: Accept an offer or reassess. If no offer after 3 months of active interviewing, revisit your target companies (you may be aiming too high) or your portfolio (you may need a more complex project or a contribution to open source MLOps tooling like MLflow or Evidently AI).
The Long Game: Growing Beyond This Roadmap
The median experience for this role is 3.7 years, but that number is falling as the field matures. Your 6-month portfolio is credible for entry-level roles. After 12-18 months on the job, you will have closed the gap entirely.
The next tier after MLOps Engineer is Staff MLOps Engineer or ML Platform Lead, typically 5-8 years in. The differentiation at that level is not technical depth but cross-functional leadership: influencing data scientists to write deployable code, convincing leadership to invest in monitoring, and mentoring junior engineers through the same roadmap you just completed.
The technology will change. Some tools you learned (Airflow, SageMaker) may fade; others (Kubernetes, FastAPI, Docker) will persist. What does not change is the engineering mindset you built: treat models as software, automate everything, monitor everything, and assume everything breaks. That mindset is your career foundation, not any specific tool.
You started with a terminal and a Dockerfile. You ended with a production-grade RAG pipeline under continuous deployment. The median experience requirement is 3.7 years. You have proven that focused execution collapses that timeline. Now go apply.
CS/Engineering degree + 3-5 yrs exp (Median 3.7 yrs)



 Group / 1: 1 Sessions
Group / 1: 1 Sessions