This roadmap is designed for professionals with a software engineering or data background who want to specialize in AI infrastructure and data engineering. The 4-6 month timeline assumes 10-15 hours per week, with an emphasis on building production-grade pipelines, not just writing queries. The key shift from traditional data engineering to AI infrastructure is understanding that data for AI is never static—you're building systems that handle drift, versioning, and real-time multimodal inputs .
Phase 1: The Pragmatic Core - SQL, Python, and the Terminal (Weeks 1-4)
Objective: Become fluent in the two languages of data engineering. Master Python for data manipulation and SQL for analytical querying before touching any distributed systems.
Beginner Focus:
Start with SQL, but go beyond basic SELECT statements. Your goal is to write complex analytical queries using window functions ( ROW_NUMBER() , LAG() , RANK() ), Common Table Expressions (CTEs), and understand query execution plans. Practice on platforms like SQL Bolt or LeetCode's database sections until you can solve medium-difficulty problems without hesitation .
For Python, shift from general scripting to data engineering patterns. Master Pandas for transformations that fit in memory, but more importantly, learn the os, glob, argparse, and logging modules. You need to write Python scripts that run unattended, handle errors gracefully, and log their progress. Practice writing idempotent ETL functions—meaning you can run the same script twice without corrupting your data .
AI Tool Usage for Learning:
Use GitHub Copilot or ChatGPT to accelerate your syntax learning. A powerful prompt for this phase is: "I have a CSV of customer orders. Write a Python script using pandas that filters out rows with null email addresses, calculates the total spend per customer, and logs the row count at each step. Then write the SQL query that would produce the same result." Let the AI generate both versions, then compare them to understand the trade-offs between procedural and declarative approaches .
Free and Paid Resources:
The free tier of DataCamp or Mode Analytics SQL tutorials is excellent for structured practice. For Python, the "Python for Everybody" specialization (free audit on Coursera) covers the fundamentals, but you must supplement it with the official pandas documentation's "10 Minutes to Pandas" guide. Paid options include the Data Engineering track on DataQuest, which focuses specifically on pipeline logic rather than data science.
Practice Exercise:
Build a local ETL pipeline that extracts data from a public API (like the OpenWeather API or a mock JSON API), transforms it by flattening nested JSON structures and renaming columns to snake_case, and loads the cleaned data into a local PostgreSQL database. Write both the Python ETL script and the SQL queries to validate the row counts after loading. Containerize this entire process with Docker so anyone can run your pipeline with docker-compose up .
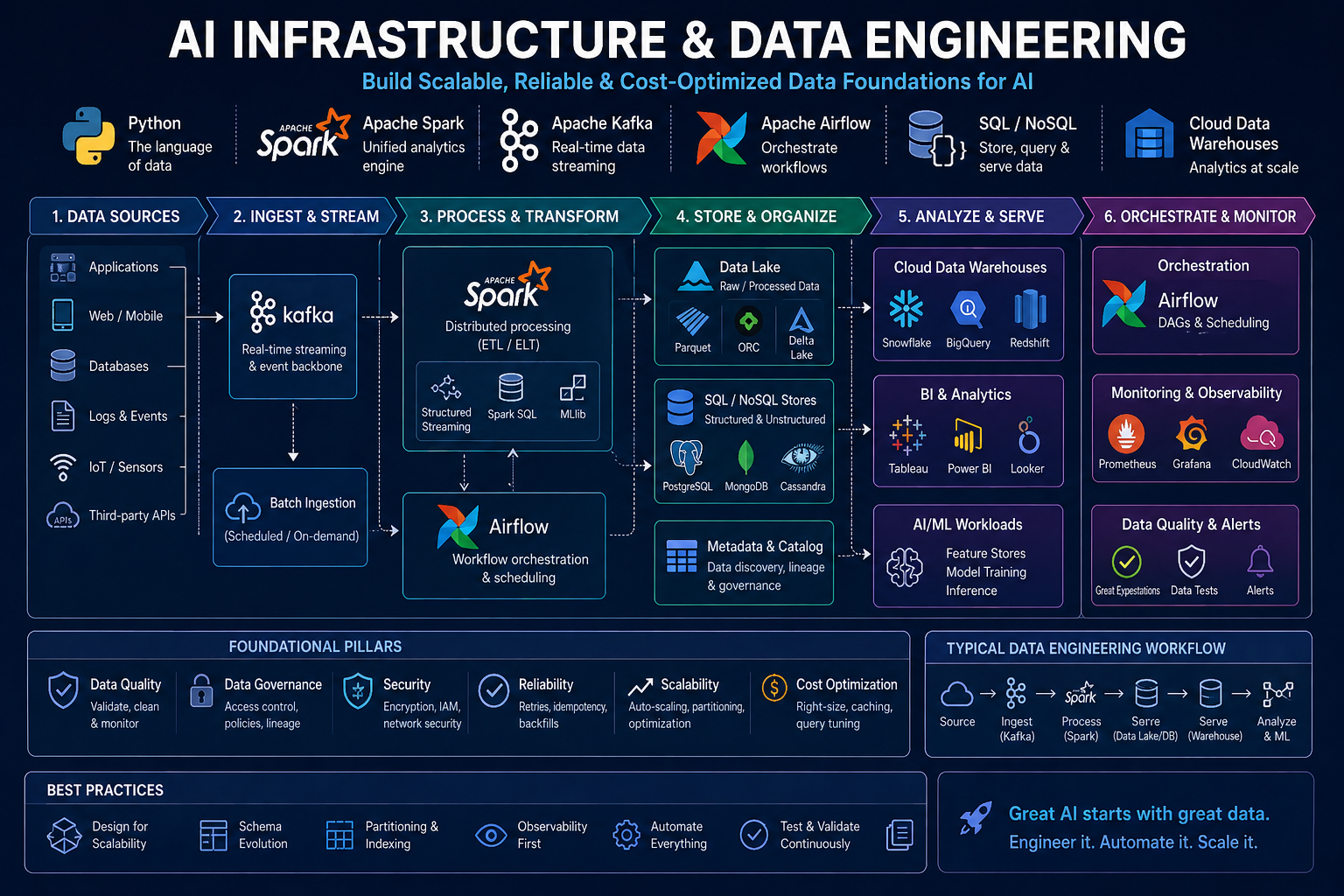
Phase 2: Distributed Data - Spark, Streaming, and the Lakehouse (Weeks 5-9)
Objective: Scale beyond a single machine. Learn to process terabytes of data with Apache Spark, handle real-time streams with Kafka, and understand modern storage patterns like Delta Lake.
Intermediate Focus:
Spark is non-negotiable for AI infrastructure roles. Skip the Spark SQL interface at first and learn the DataFrame API in Python (PySpark). The critical concept is understanding transformations (lazy) versus actions (eager). You need to know why Spark is faster than Pandas for large datasets—it distributes work across partitions. Learn to debug Spark UI to identify shuffles and skew, as this is what you'll be asked in interviews .
Next, add streaming. Kafka is the standard for event-driven architectures. You don't need to administer a Kafka cluster, but you must understand topics, partitions, producers, consumers, and consumer groups. Practice writing a PySpark Structured Streaming job that reads from a Kafka topic, performs a windowed aggregation (like "count of events per minute"), and writes the results to a console sink or a Delta table .
Finally, understand the "Lakehouse" architecture. Learn why the industry is moving from separate data lakes (S3) and warehouses (Redshift) to table formats like Delta Lake, Apache Iceberg, or Hudi. These formats add ACID transactions, time travel, and schema evolution to data lakes. Practice creating a Delta table, updating rows, and querying a previous version using the VERSION AS OF syntax .
AI Tool Usage:
Prompt the AI: "I have a PySpark DataFrame with 100 million rows. One column contains IP addresses. Write code to extract the subnet (first three octets), count occurrences per subnet, and handle the case where malformed IPs exist. Explain how this would be distributed across worker nodes." The AI will write the code, but your job is to understand the why behind the partitioning.
Free and Paid Resources:
Databricks provides a free community edition that includes a small cluster for learning Spark and Delta Lake. The official Spark documentation's "Quick Start" and "Spark SQL Guide" are essential reads. For structured learning, the "Big Data with PySpark" course on Udemy (frequent sales for $10-15) is practical. For Kafka, Confluent's free "Kafka 101" course is the best starting point.
Practice Exercise:
Build a streaming ETL pipeline. Use a Python script to simulate website clickstream data and publish events to a Kafka topic. Write a PySpark Structured Streaming job that reads these events, parses the user agent string to extract browser and OS information, windows the data into 1-minute tumbling windows, and writes the aggregated counts to a Delta table on your local disk. Then write a second script that queries the Delta table with time travel to compare the last 5 minutes of data to the previous 5 minutes .
Phase 3: Orchestration and Cloud-Native Pipelines (Weeks 10-14)
Objective: Move from ad-hoc scripts to reliable, scheduled pipelines in the cloud. Master Airflow and one cloud platform's data ecosystem.
Advanced Focus:
Apache Airflow is the industry standard for workflow orchestration. Learn the core concepts: DAGs (Directed Acyclic Graphs), Operators, Sensors, and TaskFlow API. Understand the difference between schedule_interval and catchup, and why idempotent tasks are critical for backfilling. Practice writing DAGs that have dependencies, retries on failure, and email alerts .
Choose a cloud provider—AWS, GCP, or Azure—and learn their data stack . For AWS, focus on S3 (storage), Glue (serverless Spark), Lambda (lightweight transformations), and Redshift or Athena (querying). For GCP, focus on BigQuery (serverless warehouse), Dataflow (streaming/batch with Beam), and Cloud Storage. The specific cloud matters less than understanding the serverless paradigm—you should not be managing clusters manually .
Finally, integrate data quality testing into your pipelines. Learn to use Great Expectations, Soda, or Deequ to validate data at key pipeline stages (e.g., "no nulls in ID column," "revenue > 0"). These tools integrate with Airflow to halt pipelines when data quality falls below thresholds .
AI Tool Usage:
Ask the AI: "I have a DAG with three tasks: extract from an API, transform with Spark, and load to BigQuery. Write the Python Airflow DAG using the TaskFlow API. Include a retry policy, a Slack failure notification, and a data quality check using Great Expectations between transform and load." Use the AI's output as a template, then modify the connection IDs and operator parameters for your specific environment.
Free and Paid Resources:
The "Astronomer Certification for Apache Airflow" free tutorials on YouTube are excellent. For cloud, each provider offers a free tier with credits. AWS's free tier includes 5GB of S3 storage and 1 million Lambda requests per month. The "Data Engineering on Google Cloud" specialization (free audit on Coursera) covers BigQuery and Dataflow in depth. For Great Expectations, their official "Getting Started" tutorial runs completely in a Jupyter notebook.
Practice Exercise:
Deploy an Airflow DAG (use the local SequentialExecutor or a free Astronomer account) that runs daily. The DAG should: 1) Extract data from a public API (e.g., cryptocurrency prices), 2) Use the PythonOperator to run a PySpark job in local mode that aggregates the data, 3) Write the results to a cloud storage bucket (use AWS S3 free tier), 4) Run a Great Expectations suite to validate that no price is negative, and 5) If valid, load the data into a cloud data warehouse (BigQuery sandbox is free). Configure email alerts for task failures .
Phase 4: AI-Specific Infrastructure and Advanced Patterns (Weeks 15-20)
Objective: Design data infrastructure specifically for AI workloads. Handle multimodal data, feature stores, and real-time inference pipelines.
Expert Focus:
AI infrastructure differs from traditional data engineering because it must support data for model training and inference simultaneously. Learn to build and manage feature stores—centralized repositories where features (numerical representations used by models) are stored, versioned, and served. Tools like Feast or Tecton allow you to define features once, use them for training (batch retrieval) and inference (low-latency online retrieval) .
Shift from batch to real-time architectures for AI. Learn about change data capture (CDC) with Debezium to stream database changes to Kafka, and use Kafka Streams or Flink for stateful processing. For AI inference, understand feature retrieval latency—your pipeline must serve features in milliseconds, not seconds. Practice building a pipeline where a user action produces an event, that event triggers feature retrieval from Redis, and that feature vector is sent to a model endpoint .
Multimodal AI data—text, images, audio, video—requires new storage and processing patterns. Learn to manage embedding vectors generated from LLMs or vision transformers. Vector databases like Pinecone, Milvus, or pgvector are essential for semantic search and RAG pipelines. Practice building a batch pipeline that extracts text from PDFs, generates embeddings using a pre-trained model, and indexes them in a vector database .
Finally, implement data versioning and lineage. Tools like DVC (Data Version Control) or lakeFS enable Git-like operations for data. When a model performs poorly in production, you need to know exactly which version of the training data was used. Implement data lineage tracking (using OpenLineage or Marquez) so you can trace a model's predictions back to the raw source data .
AI Tool Usage (Advanced):
Prompt the AI: *"Design a real-time feature pipeline for a fraud detection model. The pipeline should listen to Kafka topics for transaction events, join the event with user profile features from a Redis cache, compute a rolling average of transaction amounts over the last 5 minutes using Flink, and serve the final feature vector to a REST endpoint. Write the pseudocode for the Flink job and the Redis lookup."* The AI will generate the architecture; your expertise lies in understanding the latency trade-offs and failure modes.
Free and Paid Resources:
The AMD AI Academy offers free, self-paced courses on enterprise AI infrastructure, including scaling and deployment patterns. Their "Enterprise AI and Infrastructure" pathway directly addresses production AI data challenges . For feature stores, the Feast documentation includes a complete tutorial using a real dataset. For vector databases, Pinecone's free tier includes 5 million vector storage. The O'Reilly book "Data Engineering for Multimodal AI" (due August 2026) covers the entire lifecycle .
Practice Exercise:
Build an end-to-end RAG (Retrieval-Augmented Generation) data pipeline. 1) Extract text from a collection of documents (use PDFs of public domain books), 2) Chunk the text into overlapping segments, 3) Generate embeddings using a free embedding model (like Sentence Transformers), 4) Store the embeddings and metadata in a vector database (start with ChromaDB locally), 5) Build a feature retrieval API using FastAPI that takes a user query, generates an embedding, performs a similarity search, and returns the top-k relevant text chunks, and 6) Containerize everything with Docker and compose it as a single application. This project touches ingestion, transformation, feature engineering, and real-time retrieval—the core of AI infrastructure .
Final Portfolio Project: The AI Data Platform
To demonstrate competency for roles expecting a STEM degree and data engineering background, combine all phases into a single showcase project. Do not create another dashboard—create a reproducible AI data platform.
Project Title: Real-time Anomaly Detection Data Platform
- Ingestion (Kafka): Simulate IoT sensor data (temperature, pressure, vibration) published to Kafka topics.
- Streaming Processing (Spark Structured Streaming): Read from Kafka, compute rolling statistics (10-minute moving averages), detect anomalies based on z-scores, and write raw data to a Delta Lake table.
- Batch Feature Engineering (dbt or Airflow with Spark): Run nightly jobs that aggregate sensor data into training-ready features, versioned by date.
- Feature Store (Feast): Register the features (sensor_id, average_temperature_10min, vibration_spike_flag) in a feature store with both batch (for training) and online (for inference) retrieval.
- Orchestration (Airflow): A DAG that triggers the streaming job, monitors its health, starts a nightly batch feature job, and then calls a model training script if a data quality check passes.
- Cloud Deployment (AWS or GCP free tier): Deploy the Kafka and Spark components to cloud-managed services (Kinesis, EMR Serverless, or Databricks Community Edition). Store feature data in a cloud warehouse (BigQuery or Redshift).
- Data Quality (Great Expectations): Validate that the streaming pipeline processes 100% of events within 5 seconds and that batch features have no missing values.
- Lineage and Versioning (DVC + OpenLineage): Track which version of the raw sensor data generated which model training run.
This project is complex enough to discuss for an hour in an interview. It demonstrates that you understand batch, streaming, orchestration, feature serving, cloud infrastructure, data quality, and the specific patterns required for AI systems.
The median expectation for these roles is often expressed in years, but a focused portfolio with these four phases demonstrates practical competence faster than passively accumulating time. The AI tools provide the syntax and boilerplate; your engineering discipline provides the reliability and scalability.
Career Application & Next Steps: AI Infrastructure & Data Engineering
You have just completed a 4-6 month journey that transforms you from someone who writes SQL queries and Python scripts into someone who designs, builds, and operates the data backbone for AI systems. The key shift you've mastered is understanding that traditional data engineering serves dashboards and reports, but AI infrastructure serves models that must train and infer on fresh, versioned, low-latency data. Your portfolio now demonstrates streaming, batch, feature stores, lineage, and quality testing—exactly what hiring managers seek in candidates for AI-focused data roles.
Where You Fit in the Market
The role you are targeting sits at the intersection of classical data engineering and modern AI systems. You are not competing with data analysts who build Tableau dashboards. You are not competing with data scientists who tune hyperparameters. You are competing with engineers who know how to move terabytes per second, guarantee exactly-once semantics, and trace a model's prediction back to the specific version of training data that produced it.
Three primary job titles emerge from this roadmap:
AI Infrastructure Engineer: Focuses on the platforms that serve features and embeddings to models in real time. You own the feature store, the vector database, and the online retrieval layer. This role is most common in companies deploying LLMs or recommendation systems at scale.
Data Engineer (AI/ML Focus): The traditional data engineer title but with a portfolio focused on ML use cases. You build the pipelines that feed training jobs and the streaming infrastructure that powers real-time inference. Most mid-sized AI-native companies hire this role.
Platform Engineer (Data/AI): Builds internal data platforms that data scientists and ML engineers use to self-serve features and datasets. This is more common in larger enterprises with separate data platform teams.
For your first 1-2 years, target Data Engineer roles at AI-focused startups or mid-sized tech companies (200-2000 employees) with an existing ML team. Early-stage startups will expect you to build everything from Kafka clusters to feature stores without mentorship, which is risky without senior guidance. Large enterprises will place you in a narrow role (e.g., "Spark pipeline maintainer") that won't leverage your full portfolio.
Your Portfolio: The Interview Anchor
Your "Real-time Anomaly Detection Data Platform" is not just a project. It is your engineering case study. Every interview question about data infrastructure should return to this system.
Your GitHub repository must be structured for credibility. The README needs an architecture diagram showing data flow from IoT sensors to Kafka to Spark streaming to Delta Lake to Feast feature store to the anomaly detection model. Use a tool like Excalidraw or Mermaid (diagrams-as-code) so the diagram is version-controlled and reproducible.
Inside the repository, organize by phase. A streaming/ folder with your PySpark Structured Streaming job and Kafka producer script. A batch/ folder with your Airflow DAG and dbt models. A feature_store/ folder with your Feast feature definitions and registry. A quality/ folder with your Great Expectations test suites. A lineage/ folder with your OpenLineage integration. A deploy/ folder with docker-compose and cloud deployment scripts (Terraform or CloudFormation).
The documentation separates you from hobbyists. Write ARCHITECTURE.md explaining why you chose Delta Lake over Iceberg, why Spark Structured Streaming over Kafka Streams, why Feast over Tecton. Write OPS.md covering how to monitor pipeline lag, how to backfill data after a schema change, how to roll back a bad feature version. Write COST.md estimating the cloud spend for your pipeline at 1GB/day, 100GB/day, and 1TB/day scales. This signals that you think about production economics, not just correctness.
Certifications: Strategic Signal Boost
Certifications are not required, but they serve as credibility shortcuts for recruiters who cannot assess your GitHub repository. Prioritize based on your target cloud and tool stack.
For vendor-neutral data engineering, the Databricks Certified Data Engineer Associate validates your Spark, Delta Lake, and pipeline orchestration skills. This is directly aligned with your Phase 2 and Phase 3 work. The exam costs $200 and requires hands-on notebook experience, which you already have from the Databricks Community Edition.
For cloud-specific roles, choose one provider and pursue their data certification. AWS Certified Data Analytics – Specialty covers Kinesis (Kafka alternative), Glue (serverless Spark), Redshift, and Athena. Google Professional Data Engineer covers BigQuery, Dataflow (Beam/Spark), Pub/Sub (Kafka alternative), and Composer (Airflow). Azure Data Engineer Associate covers Azure Data Factory, Synapse, and Stream Analytics.
For AI-specific data roles, the Feast Certified Practitioner (if available) or a dbt Certification signals that you understand transformation workflows. However, prioritize the Databricks or cloud certification first—these have the highest recruiter recognition.
Do not collect multiple certifications. Choose one, study 4-6 weeks using official exam guides and practice tests (TutorialsDojo for AWS, Whizlabs for Databricks), pass it, and add it to your LinkedIn headline and resume summary.
Resume Transformation: From Queries to Pipelines
Your resume must speak the language of data engineering, not data analysis. Replace every instance of "analyzed data" with "built pipelines." Replace "created reports" with "produced training-ready feature sets."
Structure your resume around the four phases. Create a section "Data Engineering & AI Infrastructure" and list specific accomplishments:
- Built streaming ETL pipeline ingesting 10K events/second from Kafka, performing windowed aggregations with PySpark Structured Streaming, and writing to Delta Lake with exactly-once semantics
- Deployed Airflow DAGs orchestrating daily feature engineering jobs with task dependencies, retries, and Slack alerts, reducing pipeline failure recovery time from 2 hours to 15 minutes
- Implemented Feast feature store with both batch (training) and online (Redis) serving, enabling feature consistency across development and production
- Integrated Great Expectations data quality tests with Airflow, automatically halting pipelines when null rates exceeded 5% and sending remediation notifications
- Containerized entire data stack with Docker and deployed to AWS free tier (Kinesis, EMR Serverless, Redshift) demonstrating cloud-native data architecture
If you lack professional experience in these areas, list your portfolio project as "Independent Project" or "Capstone: Real-time Anomaly Detection Platform" with the same bullet format. The hiring manager cares that you did the work, not whether you were paid for it.
Add a "Technologies" section that includes: Python, SQL, PySpark, Kafka, Airflow, Delta Lake, Feast, Great Expectations, Docker, AWS/GCP, dbt, OpenLineage, Vector Databases (Chroma/Pinecone). Recruiters scan for these exact keywords.
Where to Find These Jobs
Job titles vary across industries. Search for these terms: AI Infrastructure Engineer, Data Engineer (ML Focus), MLOps Data Engineer, Streaming Data Engineer, Feature Platform Engineer, and Analytics Engineer (if dbt-focused). On LinkedIn, set alerts for "Delta Lake," "Feast," "Kafka Streaming," and "Airflow DAG" because job posts mention the tools before the titles.
Companies hiring for these roles fall into predictable tiers:
AI-first startups (Series B-C): Companies like Weights & Biases, Tecton, Astronomer, or any YC company building ML infrastructure. These roles are ideal because you work directly with the tools you learned. Compensation often includes meaningful equity.
Tech companies with mature ML: Uber, Airbnb, DoorDash, Spotify, Netflix all have massive data infrastructure teams. These roles are more competitive but offer the highest compensation ($150k-200k base for mid-level). Target these after 1-2 years of experience.
Traditional enterprises adopting AI: Banks (JPMorgan, Capital One), retailers (Walmart, Target), healthcare (UnitedHealth, Kaiser). These roles pay well but move slower. The advantage is job stability and the chance to lead cloud migrations.
Consulting and services: Accenture, Deloitte, Slalom have AI/data practices. These roles are project-based, giving you exposure to different stacks every 6-12 months. Excellent for rapid skill growth but demanding travel (less true post-pandemic).
The hidden job market is converting your network. Every data scientist or ML engineer you know complains about data quality, pipeline failures, or slow feature retrieval. Ask them to introduce you to their data platform manager. The gap between data science and production data engineering is vast, and the people who can bridge it are rare.
The Interview Process: What to Expect
The AI Infrastructure and Data Engineering interview typically consists of four to five rounds, and your portfolio prepares you for all of them.
The screening call (30 minutes) is conversational but technical. Expect questions like "What's your experience with streaming vs batch processing?" and "How do you handle data quality in your pipelines?" Your answer should trace your Phase 2 streaming pipeline and Phase 3 Great Expectations integration. Say "I built a PySpark Structured Streaming job reading from Kafka with windowed aggregations" and "I integrated Great Expectations with Airflow to validate before loading."
The SQL and Python screen (60 minutes) is often a live coding exercise on a platform like HackerRank or CoderPad. Common prompts: "Write a SQL query using window functions to calculate a moving average" (your Phase 1 window functions practice). "Write a Python script that reads nested JSON from an API, flattens it, and loads to a dataframe" (your Phase 1 ETL exercise). Practice these patterns until they are fluent.
The data modeling and system design round (60-90 minutes) is where your portfolio shines. The prompt might be "Design a real-time feature pipeline for a fraud detection model" or "Design a batch feature store for a recommendation system." Draw exactly the architecture from your Phase 4 project: Kafka for ingestion, Spark Streaming for aggregation, Redis for online features, Feast for feature registry, Delta Lake for batch storage. Explain trade-offs: why exactly-once semantics matter for fraud, why you chose tumbling windows over sliding windows, why you version features by timestamp.
The distributed systems fundamentals round (45-60 minutes) tests your Spark and Kafka knowledge. Expect questions like "Explain how Spark handles straggler tasks," "What happens when a Kafka consumer dies?" and "How does Delta Lake ACID work under the hood?" Your Phase 2 deep dive into Spark UI and Delta Lake time travel gives you real examples. Say "I debugged a Spark job with data skew by identifying a hot partition in the Spark UI and adding a salted key."
The behavioral round (45 minutes) focuses on incident response and trade-offs. Have a story ready about a time your pipeline broke (your streaming job fell behind, your quality check failed, your feature store had consistency issues). Use STAR format: Situation, Task, Action, Result. The action should include how you diagnosed (logs, metrics, lineage), fixed (backfill, restart from checkpoint), and prevented recurrence (added monitoring, idempotent writes).
Negotiation and First 90 Days
If you land an offer, remember that data engineers with AI infrastructure skills are scarce. Do not anchor to standard data engineering salaries. Research levels.fyi or Glassdoor for "Data Engineer" at your target company, but add 15-20% for AI specialization. Entry-level (0-2 years experience) typically ranges 110k−
110k−150k base plus equity and bonus in US tech hubs, lower in remote or non-tech regions.
Your first 90 days in a new data engineering role follow a predictable pattern:
Days 1-30: Learn the landscape. Do not propose changes yet. Map their current pipelines: What ingestion tools (Kafka, Kinesis, Pub/Sub)? What processing (Spark, Flink, Beam)? What storage (Delta, Iceberg, Hudi)? What orchestration (Airflow, Dagster, Prefect)? What quality testing (Great Expectations, Soda, Deequ)? Identify gaps compared to your portfolio (missing lineage, missing feature store, manual quality checks).
Days 30-60: Deliver a small win. Find one painful process—a pipeline that breaks weekly, a manual data quality check, a slow backfill—and automate it. If they lack data quality, implement one Great Expectations suite on their most critical table. If their Airflow DAGs fail silently, add Slack alerts. Small wins build trust faster than grand proposals.
Days 60-90: Propose a larger initiative. Based on your gap analysis, suggest implementing a feature store, migrating to Delta Lake, or adding lineage tracking. Show a small proof of concept using your portfolio code as a starting point. Demonstrate cost savings or reliability improvements with metrics. Get buy-in before building at scale.
Avoid the common trap of rewriting everything in "the right way" on day one. The existing pipelines, however messy, keep the business running. Your job is to incrementally improve while maintaining uptime.
The AI Tools Advantage in Your Job Search
The same AI tools you used to learn are now your job search force multipliers.
Use ChatGPT to tailor your resume for each application. Paste the job description and your resume, then prompt: "Rewrite my bullet points to emphasize keywords from this job description (Spark, Kafka, Airflow, Delta Lake, Feast) while keeping all claims truthful and specific."
Use Claude to practice system design interviews. Prompt: "Act as a senior data engineer interviewing a candidate for a real-time feature pipeline role. Give me a design prompt, then ask me five clarifying questions about throughput, latency, consistency, and fault tolerance. After my answer, tell me what I missed."
Use Gemini to research target companies. Prompt: "Research [Company Name] and based on their engineering blog, job posts, and public GitHub, tell me their data stack. Identify what they use for ingestion, processing, storage, orchestration, and quality. List three infrastructure gaps I could discuss in an interview."
Use GitHub Copilot to complete take-home assignments efficiently. Many data engineering interviews include a practical task: "Ingest this dataset, perform aggregations, and expose via an API." Treat it like your Phase 4 RAG pipeline—containerize it, document it, include quality checks. Deliver a complete, runnable system, not just a script.
Six-Month Post-Roadmap Plan
Month 1: Certify if you chose that path. Complete your Databricks or AWS data certification. Update LinkedIn with the credential, your portfolio link, and a new headline like "Data Engineer | AI Infrastructure | Spark, Kafka, Airflow, Feast."
Month 2: Network intentionally. Join the dbt Slack community, Locally Optimistic (data engineering community), and the Data Engineering subreddit. Attend virtual meetups for Airflow, Spark, or Feast. Find three data engineers at target companies on LinkedIn and ask for 15-minute informational interviews. Ask about their stack, their biggest pipeline failure, and their advice for someone entering the field. Do not ask for jobs. Ask for wisdom.
Month 3: Apply strategically. Target 5-10 well-researched companies per week, not 50 spray-and-pray applications. Customize each resume. Write a cover letter (or LinkedIn message to the hiring manager) referencing their specific data stack and a gap your portfolio addresses. Track your application-to-interview ratio. Below 10%? Rewrite your resume. Below 20% after 20 applications? Re-examine your target companies (too senior? wrong industry?).
Months 4-5: Interview loop. Expect 4-8 weeks from first screen to offer. Be patient and persistent. Rejections are not personal; they are mismatches in timing, stack, or level. Ask every interviewer for one specific piece of feedback. Compile the feedback. If three interviewers say "weak on streaming exactly-once semantics," re-study that topic and add it to your portfolio documentation.
Month 6: Accept an offer or reassess. If no offer after 3 months of active interviewing (say, 40-50 applications, 5-10 first-round interviews), revisit your targeting. You may be aiming too high (senior roles requiring 5+ years) or too narrow (only AI-first startups). Broaden to include enterprises adopting AI or consultancies. Alternatively, your portfolio may need an open source contribution—fix a bug in Airflow, add a feature to Feast, write documentation for Delta Lake. Contribution signals commitment beyond self-interest.
The Long Game: Growing Beyond This Roadmap
The median expectation for these roles is often expressed in years of experience, but a focused portfolio like yours closes that gap faster than passive time accumulation. After 12-18 months in a professional role, you will have converted your portfolio into production scars—the real experience that years-of-service metrics attempt to proxy.
The next tier after Data Engineer is Senior Data Engineer or Staff AI Infrastructure Engineer, typically 5-8 years in. The differentiation at that level is not deeper Spark knowledge but broader systems thinking and cross-functional leadership. You will be expected to:
- Design data architectures that serve multiple teams (training, inference, analytics) without creating data silos
- Influence product managers to design features that generate clean, lineage-trackable data
- Mentor junior engineers through the same roadmap you just completed, but adapted to your company's specific stack
- Negotiate between data scientists (who want every column) and finance (who wants to control cloud spend)
The technology will evolve. Spark may be displaced by streaming-first engines. Airflow may be displaced by declarative orchestrators like Dagster or Prefect. Feast may be displaced by embedded feature stores in databases. Delta Lake, Iceberg, and Hudi will consolidate around a standard.
What does not change is the engineering mindset you built: treat data as a product, validate quality at every stage, version everything, make pipelines idempotent, and always trace lineage from raw source to final prediction. That mindset is your career foundation, not any specific tool.
You started with SQL and Python. You ended with a streaming, batch, feature-stored, quality-tested, lineage-tracked, cloud-deployed anomaly detection platform. The median expectation is measured in years. You have proven that focused execution collapses that timeline. Now go build the data backbone for the next generation of AI systems.
STEM degree, Data Eng/Software Eng background



 Group / 1: 1 Sessions
Group / 1: 1 Sessions