Real-time streaming data engineering is one of the most in-demand specializations in 2026. Unlike batch processing, streaming requires you to think in terms of infinite, unbounded datasets where milliseconds matter. This roadmap will take you from core concepts to production-ready architectures, including how AI tools can accelerate your learning and daily work.
Phase 1: Master the Foundational Mindset & Programming Skills
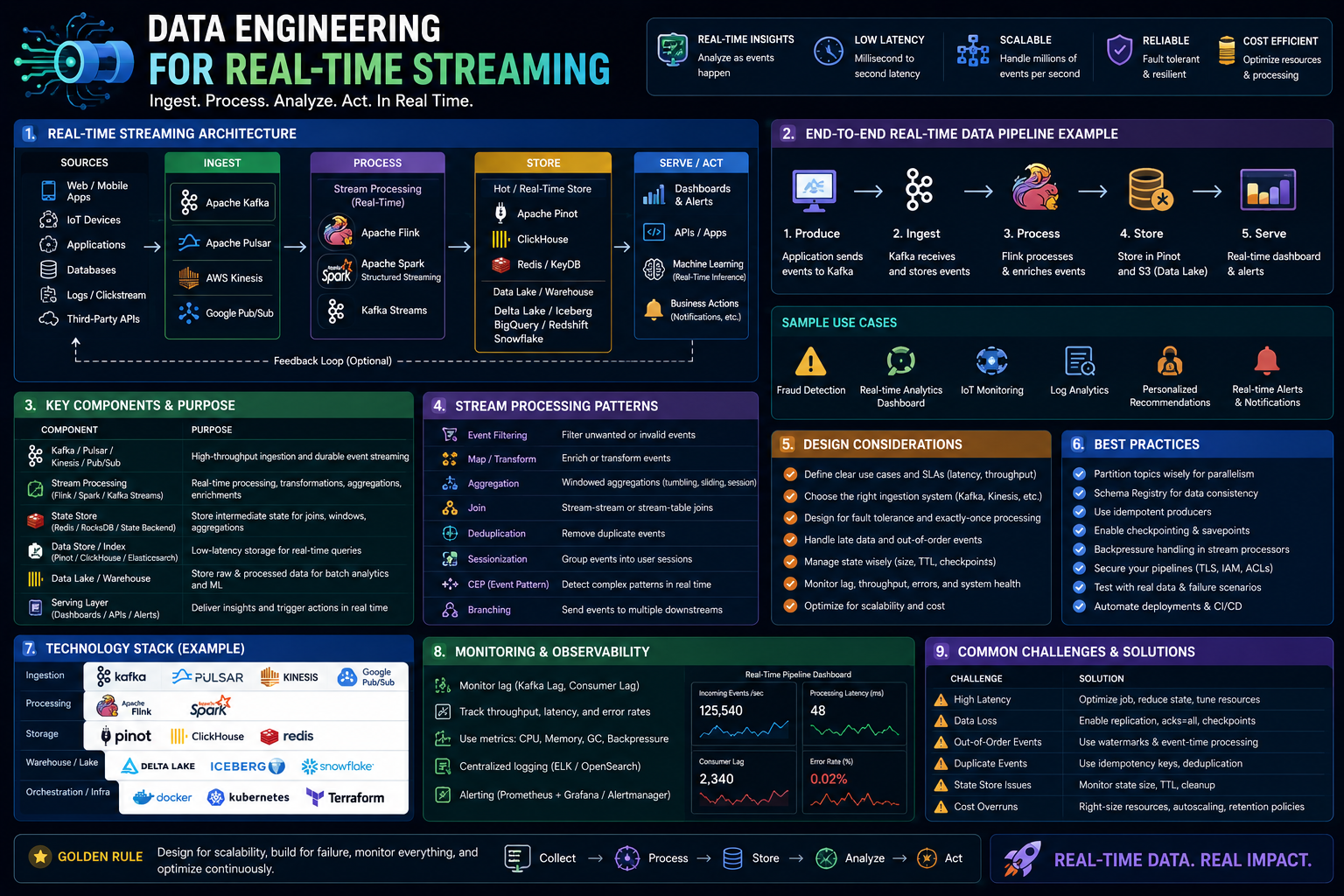
Before touching a single streaming tool, you need to internalize a key shift: streaming is not "smaller batch." Event time, processing time, watermarks, and state management are entirely new concepts. If you apply batch thinking to streaming, your pipelines will break in production.
Core Skills to Develop:
- Advanced Python: Focus on asynchronous programming, generators (for simulating data streams), and context managers. You will write producers and consumers that must run efficiently without blocking.
- Streaming SQL: Many streaming engines (Kafka ksqlDB, Flink SQL, Spark Structured Streaming) use SQL-like syntax. Master windowed aggregations (tumbling, hopping, sliding, session windows) and pattern matching.
- Event-Driven Thinking: Learn to model data as immutable events (event sourcing) rather than mutable state.
Free / Low-Cost Training Resources:
- Data Engineering Essentials (Coursera, March 2026): This newly updated course is specifically designed to bridge raw data and production-ready AI systems. Its streaming module includes hands-on labs with Apache Kafka and Apache Flink, plus a deep dive on Feature Stores to solve the "training-serving skew" problem—critical for real-time ML inference .
- Data Superstream: Becoming a Data Engineer (O'Reilly, 2024): A 3-hour video compilation featuring industry experts. Pay special attention to Adi Polak's segment on "stream processing patterns and open source software" and Jowanza Joseph's talk on "applying generative AI to data engineering problems" .
Practice Strategy:
- Use your AI coding assistant (Claude or ChatGPT) to generate a mock IoT sensor data stream. Ask it to create a Python script that sends JSON events to a local TCP socket, then write a consumer that calculates a 5-second moving average. This trains the core pattern of "ingest → transform → aggregate" in streaming.
Phase 2: Choose a Cloud Platform & Build End-to-End with Core Streaming Services
Once you understand the mental model, specialize in at least one cloud provider's streaming ecosystem. Each has its own vernacular (Kinesis vs. Pub/Sub vs. Event Hubs), but the patterns translate directly across platforms.
Option A: AWS (Most Common for Enterprise & FAANG)
AWS offers the most mature and widely-adopted serverless streaming stack. Focus on Kinesis for ingestion and Redshift streaming ingestion for analytics.
Free / Paid Resources:
- Real-Time Data Pipelines & Analytics on AWS (Coursera, September 2025): A two-module, hands-on course covering Kinesis Data Streams, Kinesis Data Firehose, AWS Glue, and Redshift. You will learn to secure streams, scale clusters, and integrate Spark with AWS services. The course includes demos on handling duplicates, scaling Kinesis streams, and fan-out patterns .
- Streaming Data Pipelines with AWS (Pluralsight, June 2025): A focused course by Lucian Lazar on building end-to-end real-time solutions. It covers configuring Kinesis Data Streams and Firehose, setting up Redshift streaming ingestion with materialized views, and optimizing performance using CloudWatch and Kinesis Data Analytics .
The Ultimate Project Resource:
- Complete AWS Data & AI Platform (GitHub Project): This is not a course—it is a production-ready reference architecture you can deploy. It simulates real-time flight delay predictions using Kinesis streaming to Lambda, then to S3, with EventBridge triggering Glue Spark ETL jobs. The value is seeing how a real-time streaming pipeline integrates with Data Science (SageMaker), MLOps (model deployment with drift detection), and even a Multi-Agent LLM chatbot that queries the streaming data from DynamoDB. Study how they use DynamoDB Streams to push WebSocket updates to a live dashboard—this is exactly what FAANG companies build .
Option B: Google Cloud (Best for AI/ML Integration)
Google Cloud excels at streaming for machine learning, with Pub/Sub (ingestion) and Dataflow (streaming processing based on Apache Beam).
Free / Paid Resource:
- Building Resilient Streaming Analytics Systems on Google Cloud (Pluralsight, November 2025): Created directly by Google Cloud, this course covers Pub/Sub for handling incoming streaming data, Dataflow for applying aggregations and transformations, and storing processed records in BigQuery or Bigtable. The course uses QwikLabs for hands-on experience .
Option C: Microsoft Azure (Best for Enterprise & Power BI Integration)
Azure streaming is tightly integrated with the Microsoft ecosystem, making it ideal for companies already using Power BI.
Free / Paid Resource:
- Building Streaming Data Pipelines in Microsoft Azure (Pluralsight, March 2026): This course focuses on Azure Stream Analytics, which uses a SQL-like language. You will learn to configure stream and reference inputs, process data using Stream Analytics Query Language, and visualize output with Microsoft Power BI .
Community Roadmap:
- LinkedIn Azure Data Engineering Roadmap (November 2025): A community-sourced post outlines a 3-month live program structure. The real-time section specifically calls out Event Hub for real-time data ingestion and Stream Analytics for streaming queries. This roadmap also emphasizes that security (Azure Key Vault) and orchestration (Data Factory) are what separate production-ready engineers from beginners . Search for "Nishant Kumar Azure Data Engineering" to find the full breakdown.
Phase 3: Augment Your Workflow with AI & GenAI for Streaming
AI is transforming data engineering by automating schema detection, anomaly detection in streams, and even generating transformation code from natural language.
Why AI Matters for Streaming:
- Anomaly Detection: AI models running on streaming data can detect fraud, sensor failures, or security breaches in milliseconds.
- Code Generation: Ask an AI to generate a PySpark Structured Streaming query to detect price spikes from a Kafka topic.
- Data Observability: AI tools can detect schema drift (when a producer sends unexpected fields) and alert you before your pipeline breaks.
AI-Focused Training & Tools:
- AI Engineering with LangChain Track (DataCamp, March 2026): This new partnership with LangChain teaches you to build and deploy AI applications at scale. While not exclusively for data engineering, it covers retrieval-augmented generation (RAG) , tool use, and agent-based systems—all of which require real-time data. The track includes an AI Tutor that provides real-time feedback on your code. This is the bridge between streaming pipelines and AI applications .
- Multi-Agent LLM Systems (Reference the AWS GitHub Project): The complete AWS project mentioned earlier includes a Multi-Agent LLM chatbot built with Amazon Bedrock. The chatbot can answer statistical questions about the real-time flight data by querying DynamoDB through an agent tool. This demonstrates a production pattern: using LLMs to provide natural language interfaces to streaming data .
How to Practice with AI:
- Take a streaming dataset (e.g., taxi trip data from NYC Open Data).
- Ask an AI assistant to generate a PySpark Structured Streaming job that reads from a simulated Kafka stream, performs a 5-minute windowed aggregation, and writes to a Delta Lake table.
- Run the code, then ask the AI to optimize it for late-arriving data using watermarks.
- Finally, ask the AI to add a drift detection alert that notifies you if the average trip distance changes by more than 20% in a 10-minute window.
Phase 4: Orchestrate & Monitor Production-Ready Pipelines
A streaming pipeline is not just about the stream processor. You need orchestration (scheduling batch jobs that complement streaming), monitoring (tracking latency and throughput), and data quality validation.
Key Skills:
- Apache Airflow or Prefect: For orchestrating batch jobs that run alongside your stream (e.g., hourly aggregations, model retraining).
- Observability: Distributed tracing (Jaeger, Zipkin), metrics (Prometheus), and logging (ELK stack).
- Data Quality: Great Expectations or dbt tests running on your streaming sink (e.g., BigQuery or Redshift).
Learning Resource:
- Data Engineering Essentials Module on Orchestration (Coursera): The same course includes dedicated sections on workflow orchestration using Airflow and Prefect, with labs on managing complex dependencies and scheduling automated triggers .
Career Application & Next Steps
Real-time streaming skills are the golden ticket into Senior Data Engineer, Streaming Platform Engineer, and Staff Data Engineer roles. According to FAANG-aligned career guides, experts who can design streaming platforms handling petabytes of data and sub-second latencies command salaries 30-50% higher than batch-only engineers .
Your immediate Next Steps:
- Pursue a Cloud-Specific Certification: After completing one of the cloud courses above, aim for the AWS Certified Data Analytics - Specialty or the Google Professional Data Engineer certification. These explicitly test streaming concepts (Kinesis, Pub/Sub, Dataflow). The knowledge you gain from the Coursera AWS course directly maps to exam domains .
- Build a Public Portfolio Project: Do not just complete tutorials. Deploy the AWS flight delay prediction project from GitHub . Modify it to use a different data source (e.g., Twitter API or cryptocurrency prices). Document your architecture, showing the streaming ingestion layer, processing logic, and real-time dashboard. This single project demonstrates six roles (Data Engineer, Analyst, Scientist, MLOps, Full-Stack, AI Engineer) working together—this is the level of cross-functional understanding FAANG companies demand .
- Practice FAANG-Style Interview Questions: The FAANG Data Engineering guide emphasizes that interviewers will ask you to design a real-time analytics platform for a hypothetical social media company. Practice explaining your choices: why Kafka over Kinesis? How would you handle late-arriving events? How would you guarantee exactly-once semantics? Be prepared to sketch architectures on a whiteboard (or digital equivalent) .
- Master the "AI-Aware" Pipeline Mindset: The highest-demand data engineers in 2026 understand how to serve features to ML models in real time. Study Feature Stores (Tecton, Feast) and practice building pipelines that both consume from streams and write to online feature stores for sub-millisecond inference. This is explicitly covered in the Coursera Data Engineering Essentials course and is a key differentiator in senior roles



 Group / 1: 1 Sessions
Group / 1: 1 Sessions